

In this post, we share some formulas for calculating the sizes of tensors (images) and the number of parameters in a layer in a Convolutional Neural Network (CNN).
This post does not define basic terminology used in a CNN and assumes you are familiar with them. In this post, the word Tensor simply means an image with an arbitrary number of channels.
We will show the calculations using AlexNet as an example. So, here is the architecture of AlexNet for reference.

AlexNet has the following layers
- Input: Color images of size 227x227x3. The AlexNet paper mentions the input size of 224×224 but that is a typo in the paper.
- Conv-1: The first convolutional layer consists of 96 kernels of size 11×11 applied with a stride of 4 and padding of 0.
- MaxPool-1: The maxpool layer following Conv-1 consists of pooling size of 3×3 and stride 2.
- Conv-2: The second conv layer consists of 256 kernels of size 5×5 applied with a stride of 1 and padding of 2.
- MaxPool-2: The maxpool layer following Conv-2 consists of pooling size of 3×3 and a stride of 2.
- Conv-3: The third conv layer consists of 384 kernels of size 3×3 applied with a stride of 1 and padding of 1.
- Conv-4: The fourth conv layer has the same structure as the third conv layer. It consists of 384 kernels of size 3×3 applied with a stride of 1 and padding of 1.
- Conv-5: The fifth conv layer consists of 256 kernels of size 3×3 applied with a stride of 1 and padding of 1.
- MaxPool-3: The maxpool layer following Conv-5 consists of pooling size of 3×3 and a stride of 2.
- FC-1: The first fully connected layer has 4096 neurons.
- FC-2: The second fully connected layer has 4096 neurons.
- FC-3: The third fully connected layer has 1000 neurons.
Next, we will use the above architecture to explain
- How to calculate the tensor size at each stage
- How to calculate the total number of parameters in the network
Size of the Output Tensor (Image) of a Conv Layer
Let’s define
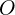 = Size (width) of output image.
= Size (width) of output image.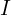 = Size (width) of input image.
= Size (width) of input image.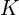 = Size (width) of kernels used in the Conv Layer.
= Size (width) of kernels used in the Conv Layer.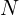 = Number of kernels.
= Number of kernels. = Stride of the convolution operation.
= Stride of the convolution operation.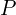 = Padding.
= Padding.
The size () of the output image is given by
![\[ O = \frac{I - K + 2P}{S} + 1 \]](https://learnopencv.com/wp-content/ql-cache/quicklatex.com-92e41171fd0073dd093c81f615d46f57_l3.png)
The number of channels in the output image is equal to the number of kernels .
Example: In AlexNet, the input image is of size 227x227x3. The first convolutional layer has 96 kernels of size 11x11x3. The stride is 4 and padding is 0. Therefore the size of the output image right after the first bank of convolutional layers is
![\[ O = \frac{ 227 - 11 + 2 \times 0 }{4} + 1 = 55 \]](https://learnopencv.com/wp-content/ql-cache/quicklatex.com-4ce0f1a3090d70d8441385a10d803a81_l3.png)
So, the output image is of size 55x55x96 ( one channel for each kernel ).
We leave it for the reader to verify the sizes of the outputs of the Conv-2, Conv-3, Conv-4 and Conv-5 using the above image as a guide.
Size of Output Tensor (Image) of a MaxPool Layer
Let’s define
= Size (width) of output image. = Size (width) of input image. = Stride of the convolution operation. = Pool size.
= Pool size.
The size () of the output image is given by
![\[ O = \frac{ I - P_s }{S} + 1 \]](https://learnopencv.com/wp-content/ql-cache/quicklatex.com-bf853f5eca40b78fea7da09debaa3858_l3.png)
Note that this can be obtained using the formula for the convolution layer by making padding equal to zero and keeping same as the kernel size. But unlike the convolution layer, the number of channels in the maxpool layer’s output is unchanged.
Example: In AlexNet, the MaxPool layer after the bank of convolution filters has a pool size of 3 and stride of 2. We know from the previous section, the image at this stage is of size 55x55x96. The output image after the MaxPool layer is of size
![\[ O = \frac{ 55 - 3 }{2} + 1 = 27 \]](https://learnopencv.com/wp-content/ql-cache/quicklatex.com-69938d79e8624e23ab9f189be6060ba5_l3.png)
So, the output image is of size 27x27x96.
We leave it for the reader to verify the sizes of the outputs of MaxPool-2 and MaxPool-3.
Size of the output of a Fully Connected Layer
A fully connected layer outputs a vector of length equal to the number of neurons in the layer.
Summary: Change in the size of the tensor through AlexNet
In AlexNet, the input is an image of size 227x227x3. After Conv-1, the size of changes to 55x55x96 which is transformed to 27x27x96 after MaxPool-1. After Conv-2, the size changes to 27x27x256 and following MaxPool-2 it changes to 13x13x256. Conv-3 transforms it to a size of 13x13x384, while Conv-4 preserves the size and Conv-5 changes the size back go 27x27x256. Finally, MaxPool-3 reduces the size to 6x6x256. This image feeds into FC-1 which transforms it into a vector of size 4096×1. The size remains unchanged through FC-2, and finally, we get the output of size 1000×1 after FC-3.
Next, we calculate the number of parameters in each Conv Layer.
Number of Parameters of a Conv Layer
In a CNN, each layer has two kinds of parameters : weights and biases. The total number of parameters is just the sum of all weights and biases.
Let’s define,
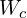 = Number of weights of the Conv Layer.
= Number of weights of the Conv Layer.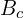 = Number of biases of the Conv Layer.
= Number of biases of the Conv Layer.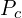 = Number of parameters of the Conv Layer. = Size (width) of kernels used in the Conv Layer. = Number of kernels.
= Number of parameters of the Conv Layer. = Size (width) of kernels used in the Conv Layer. = Number of kernels.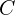 = Number of channels of the input image.
= Number of channels of the input image.

In a Conv Layer, the depth of every kernel is always equal to the number of channels in the input image. So every kernel has 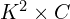 parameters, and there are such kernels. That’s how we come up with the above formula.
parameters, and there are such kernels. That’s how we come up with the above formula.
Example: In AlexNet, at the first Conv Layer, the number of channels () of the input image is 3, the kernel size () is 11, the number of kernels () is 96. So the number of parameters is given by
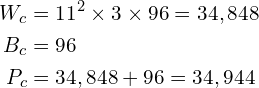
Readers can verify the number of parameters for Conv-2, Conv-3, Conv-4, Conv-5 are 614656 , 885120, 1327488 and 884992 respectively. The total number of parameters for the Conv Layers is therefore 3,747,200. Think this is a large number? Well, wait until we see the fully connected layers. One of the benefits of the Conv Layers is that weights are shared and therefore we have fewer parameters than we would have in case of a fully connected layer.
Number of Parameters of a MaxPool Layer
There are no parameters associated with a MaxPool layer. The pool size, stride, and padding are hyperparameters.
Number of Parameters of a Fully Connected (FC) Layer
There are two kinds of fully connected layers in a CNN. The first FC layer is connected to the last Conv Layer, while later FC layers are connected to other FC layers. Let’s consider each case separately.
Case 1: Number of Parameters of a Fully Connected (FC) Layer connected to a Conv Layer
Let’s define,
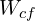 = Number of weights of a FC Layer which is connected to a Conv Layer.
= Number of weights of a FC Layer which is connected to a Conv Layer.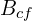 = Number of biases of a FC Layer which is connected to a Conv Layer. = Size (width) of the output image of the previous Conv Layer. = Number of kernels in the previous Conv Layer.
= Number of biases of a FC Layer which is connected to a Conv Layer. = Size (width) of the output image of the previous Conv Layer. = Number of kernels in the previous Conv Layer. = Number of neurons in the FC Layer.
= Number of neurons in the FC Layer.
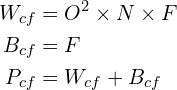
Example: The first fully connected layer of AlexNet is connected to a Conv Layer. For this layer, 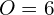 ,
, 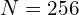 and
and 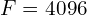 . Therefore,
. Therefore,
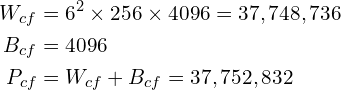
That’s an order of magnitude more than the total number of parameters of all the Conv Layers combined!
Case 2: Number of Parameters of a Fully Connected (FC) Layer connected to a FC Layer
Let’s define,
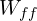 = Number of weights of a FC Layer which is connected to an FC Layer.
= Number of weights of a FC Layer which is connected to an FC Layer. = Number of biases of a FC Layer which is connected to an FC Layer.
= Number of biases of a FC Layer which is connected to an FC Layer.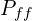 = Number of parameters of a FC Layer which is connected to an FC Layer. = Number of neurons in the FC Layer.
= Number of parameters of a FC Layer which is connected to an FC Layer. = Number of neurons in the FC Layer.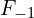 = Number of neurons in the previous FC Layer.
= Number of neurons in the previous FC Layer.
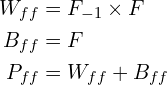
In the above equation,
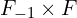 is the total number of connection weights from neurons of the previous FC Layer the neurons of the current FC Layer. The total number of biases is the same as the number of neurons ().
is the total number of connection weights from neurons of the previous FC Layer the neurons of the current FC Layer. The total number of biases is the same as the number of neurons ().
Example: The last fully connected layer of AlexNet is connected to an FC Layer. For this layer, 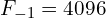 and
and 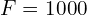 . Therefore,
. Therefore,
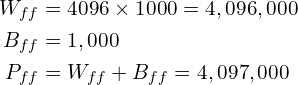
We leave it for the reader to verify the total number of parameters for FC-2 in AlexNet is 16,781,312.
Number of Parameters and Tensor Sizes in AlexNet
The total number of parameters in AlexNet is the sum of all parameters in the 5 Conv Layers + 3 FC Layers. It comes out to a whopping 62,378,344! The table below provides a summary.
| Layer Name | Tensor Size | Weights | Biases | Parameters |
| Input Image | 227x227x3 | 0 | 0 | 0 |
| Conv-1 | 55x55x96 | 34,848 | 96 | 34,944 |
| MaxPool-1 | 27x27x96 | 0 | 0 | 0 |
| Conv-2 | 27x27x256 | 614,400 | 256 | 614,656 |
| MaxPool-2 | 13x13x256 | 0 | 0 | 0 |
| Conv-3 | 13x13x384 | 884,736 | 384 | 885,120 |
| Conv-4 | 13x13x384 | 1,327,104 | 384 | 1,327,488 |
| Conv-5 | 13x13x256 | 884,736 | 256 | 884,992 |
| MaxPool-3 | 6x6x256 | 0 | 0 | 0 |
| FC-1 | 4096×1 | 37,748,736 | 4,096 | 37,752,832 |
| FC-2 | 4096×1 | 16,777,216 | 4,096 | 16,781,312 |
| FC-3 | 1000×1 | 4,096,000 | 1,000 | 4,097,000 |
| Output | 1000×1 | 0 | 0 | 0 |
| Total | 62,378,344 |

